Install Poppler on Databricks cluster
Posted on Dec 09, 2023pdf2image and easyocr. pdf2image is Python wrapper library for Poppler, which is a PDF rendering library; and is required to be installed on the cluster. 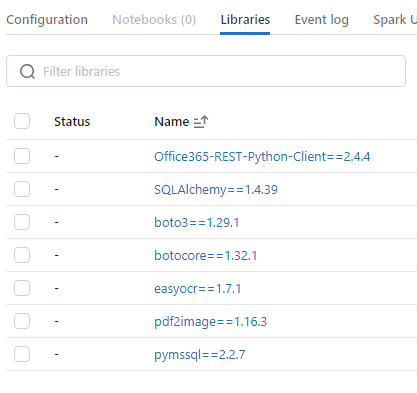
If you run the below code on the cluster you will get the following error
from pdf2image import convert_from_path
import easyocr
import numpy as np
images = convert_from_path("/Workspace/dev/my_pdf_file.pdf")
reader = easyocr.Reader(["en"])
pdf_text = ""
for idx, image in enumerate(images):
page_num = idx + 1
print(f"reading text from page {page_num}")
bounds = reader.readtext(np.array(image))
for i in range(len(bounds)):
pdf_text += bounds[i][1] + "\n"
# only read the first 4 pages
if idx == 3:
break
ERROR
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
File /local_disk0/.ephemeral_nfs/cluster_libraries/python/lib/python3.10/site-packages/pdf2image/pdf2image.py:568, in pdfinfo_from_path(pdf_path, userpw, ownerpw, poppler_path, rawdates, timeout)
567 env["LD_LIBRARY_PATH"] = poppler_path + ":" + env.get("LD_LIBRARY_PATH", "")
--> 568 proc = Popen(command, env=env, stdout=PIPE, stderr=PIPE)
570 try:
File /usr/lib/python3.10/subprocess.py:971, in Popen.__init__(self, args, bufsize, executable, stdin, stdout, stderr, preexec_fn, close_fds, shell, cwd, env, universal_newlines, startupinfo, creationflags, restore_signals, start_new_session, pass_fds, user, group, extra_groups, encoding, errors, text, umask, pipesize)
968 self.stderr = io.TextIOWrapper(self.stderr,
969 encoding=encoding, errors=errors)
--> 971 self._execute_child(args, executable, preexec_fn, close_fds,
972 pass_fds, cwd, env,
973 startupinfo, creationflags, shell,
974 p2cread, p2cwrite,
975 c2pread, c2pwrite,
976 errread, errwrite,
977 restore_signals,
978 gid, gids, uid, umask,
979 start_new_session)
980 except:
981 # Cleanup if the child failed starting.
File /usr/lib/python3.10/subprocess.py:1863, in Popen._execute_child(self, args, executable, preexec_fn, close_fds, pass_fds, cwd, env, startupinfo, creationflags, shell, p2cread, p2cwrite, c2pread, c2pwrite, errread, errwrite, restore_signals, gid, gids, uid, umask, start_new_session)
1862 err_msg = os.strerror(errno_num)
-> 1863 raise child_exception_type(errno_num, err_msg, err_filename)
1864 raise child_exception_type(err_msg)
FileNotFoundError: [Errno 2] No such file or directory: 'pdfinfo'
During handling of the above exception, another exception occurred:
PDFInfoNotInstalledError Traceback (most recent call last)
File <command-1797981490870940>, line 5
2 import easyocr
3 import numpy as np
----> 5 images = convert_from_path("/Workspace/dev/my_pdf_file.pdf")
6 reader = easyocr.Reader(["en"])
8 pdf_text = ""
File /local_disk0/.ephemeral_nfs/cluster_libraries/python/lib/python3.10/site-packages/pdf2image/pdf2image.py:127, in convert_from_path(pdf_path, dpi, output_folder, first_page, last_page, fmt, jpegopt, thread_count, userpw, ownerpw, use_cropbox, strict, transparent, single_file, output_file, poppler_path, grayscale, size, paths_only, use_pdftocairo, timeout, hide_annotations)
124 if isinstance(poppler_path, PurePath):
125 poppler_path = poppler_path.as_posix()
--> 127 page_count = pdfinfo_from_path(
128 pdf_path, userpw, ownerpw, poppler_path=poppler_path
129 )["Pages"]
131 # We start by getting the output format, the buffer processing function and if we need pdftocairo
132 parsed_fmt, final_extension, parse_buffer_func, use_pdfcairo_format = _parse_format(
133 fmt, grayscale
134 )
File /local_disk0/.ephemeral_nfs/cluster_libraries/python/lib/python3.10/site-packages/pdf2image/pdf2image.py:594, in pdfinfo_from_path(pdf_path, userpw, ownerpw, poppler_path, rawdates, timeout)
591 return d
593 except OSError:
--> 594 raise PDFInfoNotInstalledError(
595 "Unable to get page count. Is poppler installed and in PATH?"
596 )
597 except ValueError:
598 raise PDFPageCountError(
599 f"Unable to get page count.\n{err.decode('utf8', 'ignore')}"
600 )
PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
BUT WHY?
pdf2image convert_from_path() function, it is looking for the pdfinfo library on the system, which does not exists. Which is why we get this error:
PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
sudo apt-get upgrade -y
sudo apt-get install poppler-utils -y
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
libpoppler118 poppler-data
Suggested packages:
ghostscript fonts-japanese-mincho | fonts-ipafont-mincho fonts-japanese-gothic | fonts-ipafont-gothic fonts-arphic-ukai fonts-arphic-uming fonts-nanum
The following NEW packages will be installed:
libpoppler118 poppler-data poppler-utils
0 upgraded, 3 newly installed, 0 to remove and 16 not upgraded.
Need to get 3,430 kB of archives.
After this operation, 17.7 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu jammy/main amd64 poppler-data all 0.4.11-1 [2,171 kB]
Ign:2 http://archive.ubuntu.com/ubuntu jammy-updates/main amd64 libpoppler118 amd64 22.02.0-2ubuntu0.2
Ign:3 http://archive.ubuntu.com/ubuntu jammy-updates/main amd64 poppler-utils amd64 22.02.0-2ubuntu0.2
Err:2 http://security.ubuntu.com/ubuntu jammy-updates/main amd64 libpoppler118 amd64 22.02.0-2ubuntu0.2
404 Not Found [IP: 185.125.190.36 80]
Err:3 http://security.ubuntu.com/ubuntu jammy-updates/main amd64 poppler-utils amd64 22.02.0-2ubuntu0.2
404 Not Found [IP: 185.125.190.36 80]
Fetched 2,171 kB in 1s (1,689 kB/s)
E: Failed to fetch http://security.ubuntu.com/ubuntu/pool/main/p/poppler/libpoppler118_22.02.0-2ubuntu0.2_amd64.deb 404 Not Found [IP: 185.125.190.36 80]
E: Failed to fetch http://security.ubuntu.com/ubuntu/pool/main/p/poppler/poppler-utils_22.02.0-2ubuntu0.2_amd64.deb 404 Not Found [IP: 185.125.190.36 80]
E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
so, it looks like for some reason these packageshttp://security.ubuntu.com/ubuntu/pool/main/p/poppler/poppler-utils_22.02.0-2ubuntu0.2_amd64.deb and http://security.ubuntu.com/ubuntu/pool/main/p/poppler/libpoppler118_22.02.0-2ubuntu0.2_amd64.deb were removed. You can view the list of poppler packages here.
OK, HOW TO FIX THIS?
apt-get command for both libpoppler118 and poppler-utils. You can successfully install the packages on your databricks cluster.
sudo apt-get install libpoppler118=22.02.0-2 -y
sudo apt-get install poppler-utils=22.02.0-2 -y
dpkg command to see the location of the installed package.
dpkg -L poppler-utils
/.
/usr
/usr/bin
/usr/bin/pdfattach
/usr/bin/pdfdetach
/usr/bin/pdffonts
/usr/bin/pdfimages
/usr/bin/pdfinfo
/usr/bin/pdfseparate
/usr/bin/pdfsig
/usr/bin/pdftocairo
/usr/bin/pdftohtml
/usr/bin/pdftoppm
/usr/bin/pdftops
/usr/bin/pdftotext
/usr/bin/pdfunite
/usr/share
/usr/share/doc
/usr/share/doc/poppler-utils
/usr/share/doc/poppler-utils/copyright
/usr/share/lintian
/usr/share/lintian/overrides
/usr/share/lintian/overrides/poppler-utils
/usr/share/man
/usr/share/man/man1
/usr/share/man/man1/pdfattach.1.gz
/usr/share/man/man1/pdfdetach.1.gz
/usr/share/man/man1/pdffonts.1.gz
/usr/share/man/man1/pdfimages.1.gz
/usr/share/man/man1/pdfinfo.1.gz
/usr/share/man/man1/pdfseparate.1.gz
/usr/share/man/man1/pdfsig.1.gz
/usr/share/man/man1/pdftocairo.1.gz
/usr/share/man/man1/pdftohtml.1.gz
/usr/share/man/man1/pdftoppm.1.gz
/usr/share/man/man1/pdftops.1.gz
/usr/share/man/man1/pdftotext.1.gz
/usr/share/man/man1/pdfunite.1.gz
/usr/share/doc/poppler-utils/changelog.Debian.gz
Running the original code now works and we get the expected output. Showing that the pdf file is being processed.
output
reading text from page 1
reading text from page 2
reading text from page 3
reading text from page 4
…
To get the poppler-utils package installed on the cluster every time it starts, I created a simple init script to add to the configuration for cluster. This is a shell script called cluster_init.sh
# install poppler-utils on cluster
sudo apt-get install libpoppler118=22.02.0-2 -y
sudo apt-get install poppler-utils=22.02.0-2 -y
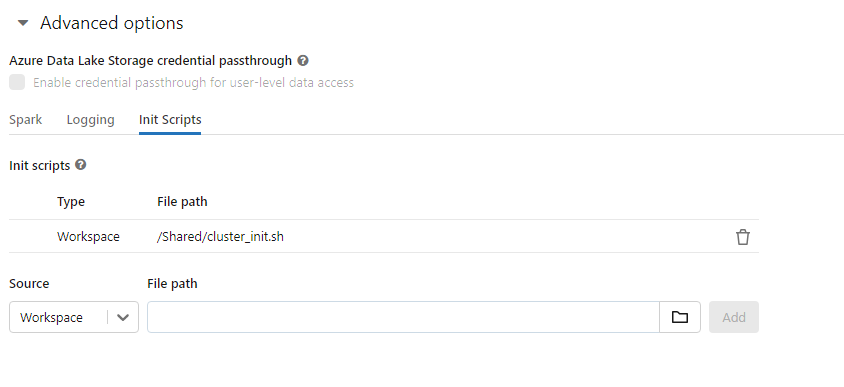
Now the cluster will always have the poppler library installed and allow the ETL to process and extract text from the PDF documents.
No Comments